Ariadne Conill 🐰
ariadne@treehouse.systems

vm.overcommit_memory=2 is always the right setting on servers: https://ariadne.space/2025/12/16/vmovercommitmemory-is-always-the-right.html
 11
11
 2
2
 0
0
I find it crazy, too, that 0 means heuristic, 1 always overcommit/never check, and 2 never overcommit/always check.
One would expect 0 to be never overcommit/always check, 1 heuristic overcommit, and 2 always overcommit/never check...
0
0
0

Ignas Kiela
ignaloidas@not.acu.lt@ariadne This only helps if applications actually check their allocations. Basically nobody does that.
2
0
0
Ariadne Conill 🐰
ariadne@treehouse.systems
@ignaloidas no, it helps even with lazily written applications.
if i write:
void foo(void) {
unsigned char *p = malloc(...);
*p = 12;
}
then if malloc returns NULL, gdb will crash and point at the line with `*p = 12` if overcommit is disabled.
2
1
0
Andrew Zonenberg
azonenberg@ioc.exchange@ariadne overcommit shocked me so much when I first learned about it. Having memory that's not really there, that can randomly segfault when you try to use it with no way to handle the error, is such a terrible idea.
I work on large scale number crunching software that can use huge amounts of memory and it's straightforward to handle running out of GPU memory, we have handlers for that. Running out of CPU side memory is always a bit of an adventure in comparison.
1
1
0
Ariadne Conill 🐰
ariadne@treehouse.systems
@azonenberg i think it made sense in the early days of Linux, but it is definitely time to move on
1
0
0
Andrew Zonenberg
azonenberg@ioc.exchange@ariadne I'd say the opposite. The less memory you have the more important it is to a) account for every byte and b) gracefully handle running out
If you have 192GB on every workstation and aren't someone like me who will OOM anyway working on huge images and such, you'll probably never run onto a problem overcommit would have helped you with anyway.
If you have 128 MB you *will* run out.
2
0
0
Ariadne Conill 🐰
ariadne@treehouse.systems
@azonenberg i'm talking like the days when we had 8MB of RAM, i could see why people would find this feature advantageous in such a scenario
2
0
0
Ignas Kiela
ignaloidas@not.acu.lt@ariadne congratulations, now you’ve turned harmless overcommits into similarly unhadleable crashes
also, such approach kills memory occupancy - because there is a lot of memory wasted (think Vector<> and the like), and overcommit allows that to be siliently ignored, while for strong allocation, any such thing will just end up wasting space that other programs could use.
1
0
0
Andrew Zonenberg
azonenberg@ioc.exchange@ariadne and in such a case you want to be able to gracefully degrade, drop a connection or push some state to disk or something instead of just crashing.
0
0
0
Colin
colinstu@birdbutt.com@ariadne @azonenberg this was added way back in kernel 2.6.. and exactly yeah my thoughts too.
0
0
0
Haelwenn /элвэн/ 
lanodan@queer.hacktivis.me
@ariadne @ignaloidas Yeah, sadly from like a user point of view it does makes software more crashy (and good luck talking to most devs about error handling around memory allocation).
So I have vm.overcommit_memory=0 on client machines (mostly due to glib), but vm.overcommit_memory=2 on servers.
0
0
0
Ariadne Conill 🐰
ariadne@treehouse.systems
@ignaloidas also, nothing stops the STL implementation from using memory holes in Vector<>, pages mapped read-only are not counted as wired. they just don't get it "for free", as they don't get it "for free" on literally every other kernel.
0
0
0
Wesley Moore
wezm@mastodon.decentralised.social@ariadne I was having issues with the OOM killer taking out my whole session, so I tried disabling overcommit (notes attached). I then found that allocations were being rejected when there was still plenty of free RAM. I found the docs and general idea of the `overcommit_ratio` confusing, but tried tweaking it, and was still getting failed allocations with free memory. So I turned overcommit back on and set up earlyoom instead. You don't run into this problem with it turned off?
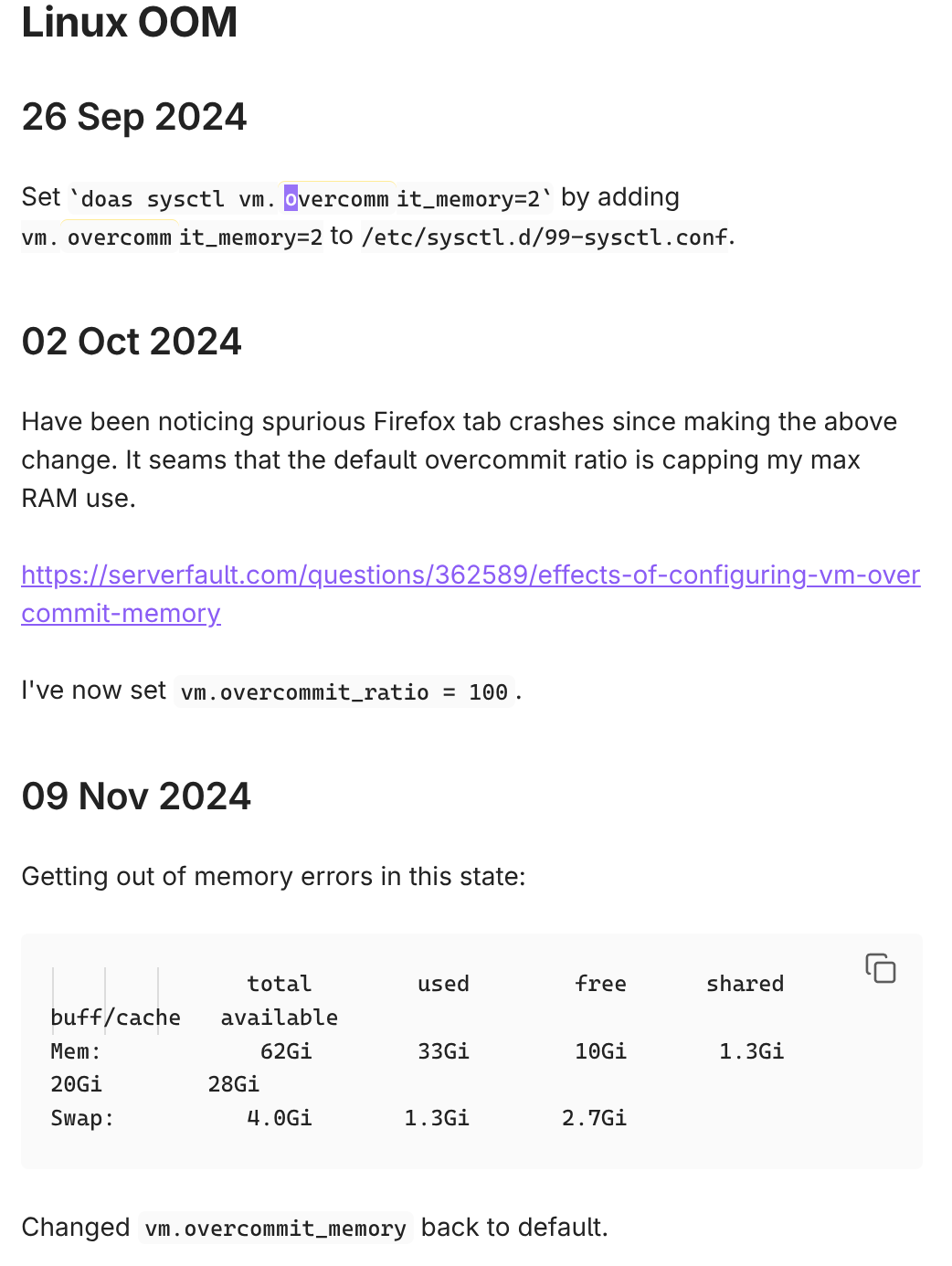 1
0
0
1
0
0
Ignas Kiela
ignaloidas@not.acu.lt@ariadne and do what? Crash?
Also such approach stops protections like Chrome’s sandboxed pointers from working https://docs.google.com/document/d/1HSap8-J3HcrZvT7-5NsbYWcjfc0BVoops5TDHZNsnko/edit?tab=t.0#heading=h.suker1x4zgzz
3
0
0
Andrew Zonenberg
azonenberg@ioc.exchange@ariadne I mean my current embedded projects are on systems with 564 or 808 kB of total RAM.
I don't even have a heap. I want fully static memory allocations so I can be sure I'll never run out unexpectedly.
0
0
0
Laurent Bercot
ska@treehouse.systems@ignaloidas @ariadne as always I'm glad to be in the good company of nobody
1
0
0
Ariadne Conill 🐰
ariadne@treehouse.systems
@ignaloidas no it doesn't, they just map the 1TB range read-only and then map individual pages in as needed, just like with Vector<>.
if you are doing systems programming, then yes, you are going to have to *do systems programming* to obtain correctness. i don't know what to tell you.
1
0
0
Norm Mikoto
mikoto@akko.wtf
1
0
0
Ignas Kiela
ignaloidas@not.acu.lt@mikoto @ariadne what else but crash? If anyone thinks any appreciable percentage of programs handle memory allocation failures any more gracefully than a log message and exit is delusional
David Chisnall posted about this like a month ago https://infosec.exchange/@david_chisnall/115577388690783690
1
0
0
Ariadne Conill 🐰
ariadne@treehouse.systems
@ignaloidas @mikoto you were being asked how chrome sandboxed pointers work on windows
1
0
0
Kraftwerk-Das Model Collapse
dngrs@chaos.social@ariadne
> Code that requires overcommit to function correctly is failing to handle memory allocation errors correctly.
just ... wow.
(I 100% agree with your sentiment)
0
0
0
Ignas Kiela
ignaloidas@not.acu.lt@ariadne @mikoto ah, misread the question, thought that was in response to the first part
Windows has specific allocators for virtual memory https://learn.microsoft.com/en-us/windows/win32/memory/reserving-and-committing-memory
1
0
0
Ariadne Conill 🐰
ariadne@treehouse.systems
@ignaloidas @mikoto yes, so does linux. and chrome already uses them correctly!
1
0
0
Haelwenn /элвэн/
lanodan@queer.hacktivis.me
a. Simply propagating the error down
b. Cancelling the new action (like a server refusing a new connection, browser not opening a new tab, …)
c. Writing an error message, flushing buffers, … and terminating
Also on the error message thing:
- Can take much less memory than the malloc call (can be useful for some GUIs)
- Can be done with pre-allocated buffers (good enough fallback on GUIs)
- Can be a static buffer, or even a static string (CLIs are 100% fine with this)
1
0
0
Wesley Moore
wezm@mastodon.decentralised.social@ariadne Interesting, I would have never suspected that. This was across a couple of months on an Arch system, so would have covered multiple versions of the stable kernel. Do you set `overcommit_ratio` to a specific value?
1
0
0
Ariadne Conill 🐰
ariadne@treehouse.systems
@ignaloidas @mikoto like, seriously, if you just want a VMA that isn't backed by anything, you can do that with a read-only MAP_ANONYMOUS mapping
0
0
0
Ariadne Conill 🐰
ariadne@treehouse.systems
@wezm to be clear, as redis was the example here, i am talking about *server* deployments
1
0
0
Wesley Moore
wezm@mastodon.decentralised.social@ariadne oh I see. From "is always the right setting" I assumed you meant all systems.
1
0
0
Ariadne Conill 🐰
ariadne@treehouse.systems
@wezm well, i do, and i will point to basically any non-Linux Unix system as an example that disabling overcommit should work fine on desktop (and if it isn't, there are either kernel bugs, or desktop applications that need to be fixed)
0
0
0
Ignas Kiela
ignaloidas@not.acu.lt@lanodan @ariadne
a. propagating the error down = equivalent of crashing for 99% of programs
b. that’s the perfect case for a.
c. that’s still a crash from a user perspective, just graceful, essentially the ‘handle the error by propagating it again’ case of a.
Most software will result in neither, because most software doesn’t care about allocations.
Hi I’d like to handle allocation failures in Python. Hey, can I allocate the memory for that Java object? Hey, I wonder if the database results I requested will fit into memory when I map them into Active Record objects? - All statements by the utterly deranged.
2
0
0
Haelwenn /элвэн/
lanodan@queer.hacktivis.me
Which kind of makes me wonder, when say you get a "filesystem full" error, do you also just crash the whole application instead of say prompt the user to save elsewhere?
1
0
0
Ariadne Conill 🐰
ariadne@treehouse.systems
in Python it does bubble up as an `AllocationError`, just FYI.
and besides, this is clearly about servers. i updated the title to clarify.
0
0
0
Ariadne Conill 🐰
ariadne@treehouse.systems
@ignaloidas @lanodan on servers? several years ago.
0
0
0
Ignas Kiela
ignaloidas@not.acu.lt@ariadne cool, I’m not doing systems programming, so let me write shit code that does shitty things with allocations
I honestly think you’re trying to find windmills by advocating for disabling over-commit. The industry is piled in shit, and this is the last improvement that’s needed for correctness. I’d much rather people work on moving stuff into memory safety and efficiency, rather than go fix a whole bunch of crashes popping up because apparently the kernel accurately counting actual usage is apparently bad.
1
0
0
Ariadne Conill 🐰
ariadne@treehouse.systems
@ignaloidas you're not, the supplier of your STL, however, is.
also it is rich that you think allocation correctness is not an important memory safety issue. it is actually the most important.
1
0
0
Laurent Bercot
ska@treehouse.systems@ignaloidas @ariadne I think it's the first time I see someone argue against checking malloc's return value, while suggesting they don't understand the difference between a crash and a clean exit
1
0
0
Ariadne Conill 🐰
ariadne@treehouse.systems
@ignaloidas @ska i never implied the default should be changed, even if i *personally dislike it*, which *i am allowed to do*
0
0
0
Haelwenn /элвэн/
lanodan@queer.hacktivis.me
And of course the OOM Killer just picks whatever program on heuristics, sometimes one that's actually badly using up the memory, or a legitimate one.
The funniest of the ones I had being Inkscape, which at some point had a huge memory leak, imagine working on an image only to have it get killed and not even having a coredump, so you have to reproduce the bug but coredump it manually and then try to find where the leak is.
(I instead pretty much permanently gave up on using inkscape for anything serious)
0
0
0
Laurent Bercot
ska@treehouse.systems@ignaloidas @ariadne For the record, I use overcommit on my personal machines, with a value of 2 and a ratio of about 140%. Which is more than I need, but, eh. I also have a large swap disk, so if I wanted I could disable overcommit and be perfectly okay.
I have also worked on embedded devices where not disabling overcommit would have been a very bad idea, as would have been not checking malloc's return pointer against NULL.
Overcommit really is a band-aid to accommodate lazily written programs that allocate large swaths of memory that they don't use entirely. It exists because we live in the real world; that doesn't mean we should fully depend on it.
0
0
0
Ignas Kiela
ignaloidas@not.acu.lt@ariadne I feel like UAF and buffer overruns tend to be way, way more harmful. allocation failure handling is very much a tertiary concern, if that.
If applications really want to handle allocation failures, there should be a mmap flag in linux that does just error if it fails to reserve at allocation - then those who believe that they get a benefit can handle the errors, without introducing needless crashes for others.
1
0
0
Ariadne Conill 🐰
ariadne@treehouse.systems
@ignaloidas it should be the opposite, MAP_NORESERVE, which already exists.
2
0
0
Ariadne Conill 🐰
ariadne@treehouse.systems
@ignaloidas like i understand your points, and to be clear i do run overcommit on my desktop because it's the only way to let desktop apps with suboptimal memory management (read: basically all of them) work.
on server, however, you bet your ass i want every allocation accounted for, which is why the blog calls out Redis and not, say, KDE
1
0
0
James Henstridge
jamesh@aus.social@ariadne The main argument I see in favour of overcommit is the fork() system call. With overcommit disabled, the system needs to assume that all the copy-on-write pages will be modified and reserve that amount of memory. When for most use cases, most of that memory remains shared.
With overcommit disabled, an application that uses large amounts of memory could fail to spawn another program via fork+exec, even though both programs would fit within memory.
Maybe the answer is to use fork() less, but that is a pretty big change to the unix architecture.
1
0
0
Ariadne Conill 🐰
ariadne@treehouse.systems
@jamesh fork+exec should almost always be vfork+exec anyway
1
0
0
Ignas Kiela
ignaloidas@not.acu.lt@ariadne ok cool
then you do know why redis suggests having overcommit, right? It forks for writing snapshots (utilizing the CoW functionality of fork), and that doesn’t go well without overcommit if you’re running close to the total memory capacity. And since in theory CoW could double the total memory usage of a process, that’s where the strict memory usage checker would stop it.
Without CoW, redis would have to fully stop doing anything to make a snapshot. With, it can just run through because the fork in practice never runs long enough to cause enough stuff to be modified that would have to get actually duplicated.
1
0
0
Ariadne Conill 🐰
ariadne@treehouse.systems
@ignaloidas yes, i am suggesting two things:
1. redis should properly log when background save fails due to the working set being too large, rather than telling people to turn on overcommit with a scary warning message.
2. system operators use this information to size their machines correctly, and thus not overload them, as overcommit can allow.
2
0
0
Ariadne Conill 🐰
ariadne@treehouse.systems
@ignaloidas also with things like PSI and transcedent memory, you need to run with overcommit disabled so that:
1. PSI accurately reflects the actual amount of memory pressure the machine is under, instead of under-reporting it
2. in the case of transcedent memory, more memory can be donated from a remote machine (or peer VM, or whatever)
0
0
0
Ignas Kiela
ignaloidas@not.acu.lt@ariadne ok, congratulations, you now need 2x the ram in the machine than you actually use, just in case in the entire working set of redis gets changed in the miliseconds it takes to make a backup
have fun wasting RAM with that
1
0
0
Ariadne Conill 🐰
ariadne@treehouse.systems
@ignaloidas no. you need 2x the ram to accommodate growth of the working set over time. that the background save is failing due to being unable to duplicate the working set is a warning sign that you need to either resize the machine or shard the working set.
you call it wasting RAM, i call it assured reliability.
1
0
0
Ignas Kiela
ignaloidas@not.acu.lt@ariadne You’re still wasting half your ram most of the time, and once you go over that you lose your backups - that’s the opposite of reliability
You solve these things with proper monitoring, not saying “oh, the backup failed because it couldn’t double the ram usage, guess I need a bigger machine now”
1
0
0
Ariadne Conill 🐰
ariadne@treehouse.systems
@ignaloidas all of this is honestly moot because you shouldn't be depending on redis BGSAVE as "backups" anyway. you should be sharding and using live replication for backups.
i grow tired of this conversation. i run my servers with overcommit disabled and will be continuing to do so.
if you want to continue it, i am happy to just block you at this point.
1
0
0
ground024
ground024@mastodon.gfc.rocks@ariadne You've at least one convert now. Appreciate the tip and the sound reasoning behind it.
0
0
0
Noisytoot
noisytoot
1
0
0
Ariadne Conill 🐰
ariadne@treehouse.systems
@noisytoot @ignaloidas i am aware of this, i am just saying that if anything there should be a new mode which allows that. that way we can safely overcommit where it makes sense.
1
0
1
Noisytoot
noisytoot
1
0
2
khm
khm@hj.9fs.net
1
1
0
Wolf480pl
wolf480pl@mstdn.io@ariadne
You make it seem like it's a difference between crash now and crash later.
But a lot of the time it's a difference between crash now and don't crash at all, because the program doesn't actually need that memory.
Also, does a successful allocation really prevent memory pressure from making the system unusable by evicting binaries from page cache? From what I'm reading, readonly file backings count as zero bytes...
@ignaloidas
1
0
0
Wolf480pl
wolf480pl@mstdn.io@ariadne
Also, if a program doesn't handle allocation failure, don't you get a crash at the first write to the not-really-allocated memory, regardless of overcommit? Is a null dereference some time after any easier to debug than an OOM some time after?
@ignaloidas
0
0
0
pixx
pixx@merveilles.townToday, and it cost me several hours that should have been spent on more important work, _for $DAYJOB_.
It killed the single most important process on the machine, instead of the shitty one that asked for all the RAM at once.
Found /proc/$PID/oom_score_adj, so at least it won't do this again, but this is the third or fourth time in the last two weeks that the OOM killer has triggered - though fortunately, this was the only one that actually resulted in files _disappearing_ because some applications _really did not handle that well_.
Moreover, the application that was killed has a static allocation of memory, on startup, and _literally never allocates_ after that. There is literally no situation in which it getting killed makes even a lick of sense.
1
0
0
pixx
pixx@merveilles.townAnd this is on my _desktop_. Which has 64G of DDR5 (which... was significantly cheaper when this machine was built >_<)
1
0
0
pixx
pixx@merveilles.townI actually think there's a decent argument to be made that overrcommit can make sense _in some contexts_; the problem is that the implementation is so utterly atrocious on Linux in particular that it's just not acceptable.
See, there's an entirely orthogonal problem that I think has been, at best, _implied_ here: with overcommit disabled, the error _always_ goes to _whomever asks for the memory_ when it's not available.
With overcommit enabled, instead, the OOM kill may very well go to a process that was well-behaved.
In essence, turning on overcommit is changing an implied secondary setting that also changes the semantics of _what process_ gets the error; IMO, overcommit itself is probably good in a lot of situations, but this secondary setting that comes bundled with it is incredibly stupid.
0
0
0
Tammi 𝆮 𓃠
tammeow@cute-spellcasting-ideas.eu@noisytoot @ariadne @ignaloidas if you find a mail discussion on this, please link it. i am quite curious as well. i may dig into the kernel source tree for it as well later myself
0
0
0
Hoshino Lina (星乃リナ) 🩵 3D Yuri Wedding 2026!!!
lina@vt.social@ariadne @ignaloidas I feel like you two are talking past each other and there must be a bigger elephant in the room here.
Does a large RSS fork() really fail if there isn't 2x the RAM+swap available, immediately, without overcommit? If so, you have bigger issues than redis bgsave tricks. Like any high RSS process being unable to do a simple fork/exec to launch a child executable.
And like, libraries will do fork/exec behind your back. You can't even know reliably that it won't just happen.
If that's really what happens, then having overcommit disabled is also unusably broken (for some, otherwise innocent use cases). Surely there is some middle ground behavior where this could be made to work more reasonably than the current two extreme options.
2
0
0
Hoshino Lina (星乃リナ) 🩵 3D Yuri Wedding 2026!!!
lina@vt.social@ariadne @ignaloidas Like for example, the kernel could attempt to not account fork CoW mappings as extra commit immediately, but defer to the copy. New memory allocations exceeding the *current* memory commit limit fail fast. If a CoW consumer begins touching memory to increase usage, then it wouldn't fail, but some random allocation happening elsewhere would at the point where accounting says you're out of commit (this is no different than a random app crashing with overcommit disabled; the "fail fast at the culprit" thing only works for large allocations, with slowly increasing memory usage there's no telling if the allocation that's going to fail is an actual leaker or an unrelated process). If the CoW consumer goes too fast and nothing else is allocating to the point you run out of real RAM then you're back at OOM killer.
Surely this makes more sense than "fork instantly doubles your memory commit"?
1
0
0
Ignas Kiela
ignaloidas@not.acu.lt@lina @ariadne as far as I can tell, yes. This simple program to me results in failure to fork if I have vm.overcommit_memory=2
#include <sys/mman.h>
#include <unistd.h>
#include <stdio.h>
int main()
{
void *a = mmap(0, (size_t) 2 * (size_t) 1024 * 1024 * 1024, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
perror("");
int b = fork();
printf("%d \n", b);
perror("");}
0
0
0
Ariadne Conill 🐰
ariadne@treehouse.systems
@lina @ignaloidas yes, i think this would be more sane, in combination with MAP_NORESERVE working in this mode. the point is that the current overcommit design lets people get into trouble too easily, and the OOM killer is not a cure
0
0
0
Elladan
elladan@kind.social@ariadne the thing is, the problem with overcommit is that when you run out of RAM, a random victim gets killed. But if you turn off overcommit, when you run out of RAM, a random process has the next allocate fail. Both outcomes are undesirable because they're not localized to the process using too much RAM!
It seems to me like the better approach is to have cgroup memory limits (and swap) configured, to at least localize the error.
0
0
0